2018年的深度学习热度依旧,但是已经有不少学者看到了这一波深度学习浪潮中炒作的意味。Piekniewski在‘’AI严冬降至“一文中提到,在机器学习领域的大牛们的热情似乎有所消退:Google的DeepMind团队在AlphaGo Zero之后沉寂了很长时间没有推出新的研究成果,Yann Lecun也不再担任Facebook AI的首席科学家。
尽管2018年的NIPS会议热度依旧,但是作为投资者,需要谨慎看待被过高的期待淹没的机器学习:
不要过分关注团队算法的模型复杂程度,因为实际应用中复杂模型往往是白白消耗算力的,Netflix也因此没有使用在百万美元算法竞赛中获胜的算法。
关注AI应用领域能否收集到可靠数据,建立在脏数据上的算法就是胡说八道。
AI应用场景分高容错率和低容错率场景,任何低容错率场景下算法都只能做到辅助,不能生成独立决策。
其实目前,人工智能存在的许多问题都是有迹可循的。下面以几个近期的热点作为这篇文章的开头。
热点一:研究人员发现,每当影星安妮海瑟薇有新片上映时,巴菲特的哈撒韦公司股票就会上涨。经过分析发现,由于AI选股时,误将海瑟薇当作了哈撒韦(二者的英文都是Hathaway),导致NLP分析的失误。
热点二:Google翻译出现过一个“我浙天下第一”的事件:“Beijing University is better than Zhejiang University”会被翻译为"浙江大学比北京大学好"。“Zhejiang University is not good than Beijing University”则同样被翻译为“浙江大学比北京大学好”。在北京大学的位置将其他大学带入同理,浙江大学就在Google翻译里天下第一了。(关于Google翻译的翻译错误也有许多中日互译的例子,在这里不赘述了)
热点三:关于携程的大数据杀熟事件:不少用户发现,用不同的手机型号在携程上预定同一家酒店,价格是不同的。手机型号越新,价格越高,苹果手机显示价格比安卓机普遍高。
事实上,这几个例子已经反映了在人工智能中几个最为重要的问题。下文中,我们将做详细分析。
人工智能的特点
人工智能区别于人的智能,是采用计算机,对人的思考、认知过程的程序化模拟,其中主要包括对人推理,表示问题,解决问题,合理规划,学习过程等的模拟。其中,主要使用的方法就是机器学习(Machine learning)。那么,我们可以从机器学习的定义中以小见大,看到人工智能的一些特点。
Machine learning is a field of computer science that often uses statistical techniques to give computers the ability to "learn" (i.e., progressively improve performance on a specific task) with data, without being explicitly programmed.
Wikipedia上对机器学习的定义是:采用统计方法,在没有显式编程(这里的显式编程指的是按照线性逻辑进行的串行编程)的条件下,从数据中进行学习的计算机科学。从这个定义中,我们可以提取到机器学习的一些特点:
机器学习是一种计算机科学。(这就意味着因为计算机是有极限的,机器学习就是有极限的。)
机器学习是没有显式编程的。(这是对人学习过程的模拟,因为人的学习过程并不是机械的输入输出,而是需要人脑的消化理解的,所以机器学习想最大程度的做到这一点。)
机器学习是基于数据输入的。(任何机器习得的内容是从人工输入的数据中得到的,这就意味着计算机还是不具备对输入数据的认知的,因此不能很好的做到判断输入数据的合理性。)
这些特点可以反映出机器学习的巨大优势,但是也决定了机器学习存在的主要问题。下面我们就从这三个特点入手,有针对性的从中看到机器学习,乃至人工智能的弱点。
人工智能的极限
上世纪30年代,图灵提出了三个问题:
世界上是否所有数学问题都有明确的答案。
如果有明确的答案,是否可以通过有限次的计算得到答案。
对于那些可以通过有限次的计算得到答案的数学问题,是否有一种假想的机械,让他不断运动,最后当这个机器停下来的时候,那个数学问题就能得到解决。
通过图灵设计的这种方法得到的数学模型,就是图灵机。图灵机涵盖了目前所有的计算机,所以从这3个问题中,我们可以看到人工智能的极限体现在两个方面;第一方面存在于计算机可以解决的问题的最大集合,另一方面存在于计算机算力的极限。
任何通过图灵机寻找超出这些极限的问题的答案,其实都是危险的。
计算机可解决的问题
吴军老师在《为什么计算机不是万能的》一文中,给出了人工智能可以处理的问题的极限:
首先,一个问题是否是数学问题,基础是我们的输入和输出是否是可量化的,而世界上可量化的变量本身就是有限的,比如,对风险的量化,对人的决策过程的量化,很多模型都是不和实际的。
其次,我们需要考虑数学问题是否有解,有解的问题是否可以计算得出的。有显性解的问题固然最好,对于没有显性解的问题,是否可以通过数值方法得到近似解。
从这两个范围筛选下来,基本可以得到计算机能解决的问题的最大范围。这就决定了我们人工智能的局限性。
图片来源:吴军.为什么计算机不是万能的
算力的极限
我们对于任何问题的解决,我们都需要给定时间范围。也就是说,对于一个需要在一天之内得到答案的问题,如果图灵机最短需要两天才能解决,那么即使这个问题是图灵机可以解决的问题,对于我们依然是无效的。
这里我们根据时间复杂度(不单纯是解决问题所需要的时间,而是当问题规模扩大后,程序需要的时间长度增长得有多快)对可解的数学问题进行划分:
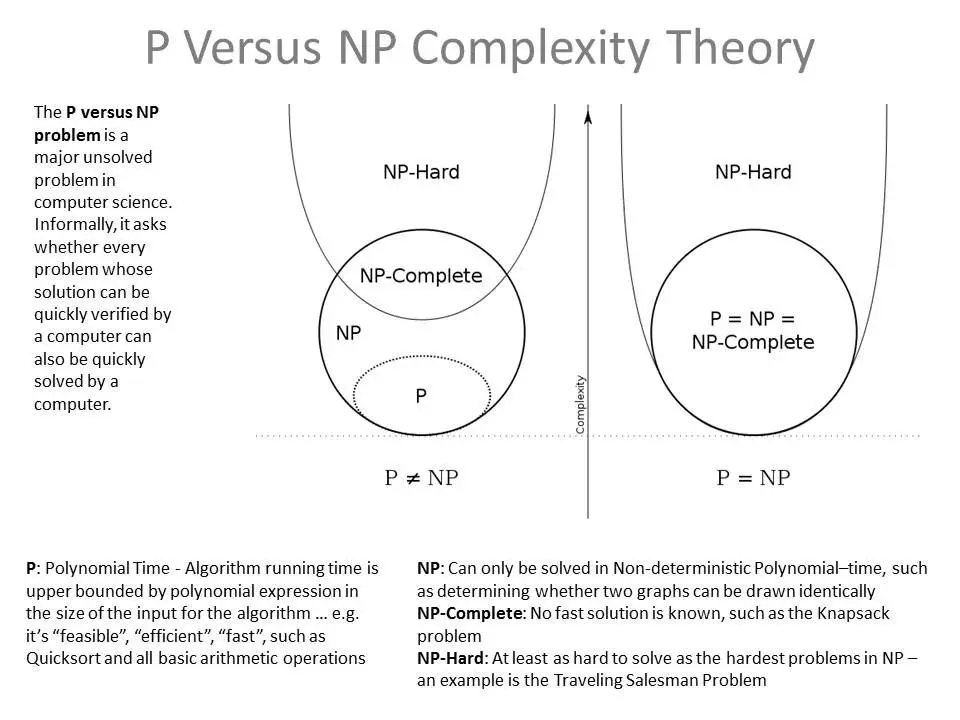
P问题(Polynomial Problem):在多项式时间内能被确定机(通常意义的计算机)解决的问题。简单的说,就是随着需要处理数据量大小的增长,需要解决问题的时间成多项式方式增长。
NP问题( Non-Deterministic Polynomial Problem):在多项式时间内被非确定机(简单的理解,就是没有一个显性的公式可以是我们得到答案,但是我们可以通过穷举的方式得到答案)解决的问题。(对于NP是否和P相同,目前我们还没有结论,因为我们不能确定NP问题的显性解是我们没有找到还是不存在。)
NP完全问题(NP-Complete Problem):NP问题中的某些问题的复杂性与整个类的复杂性相关联。这些问题中任何一个如果存在多项式时间的算法(是P问题),那么所有NP问题都是多项式时间可解的.这些问题被称为NP-完全问题(NPC问题)。NP完全问题是决定P问题和NP问题是否完全相同的关键。
NP难问题(NP-Hard Problem):时间复杂性不少于NP问题的问题。
以上的问题在我们输入规模很小的时候,任何算法都能得到有效的解决。但是随着输入规模的扩大,能找的最优方法所需要的时间至少是幂次增长的,甚至是指数增长的。那么,算法一定时,如果我们需要在一定时间内解决问题,能够采取的方法就是扩大计算规模。但是算力是存在严格的物理极限的。
勃瑞姆曼极限(Bremermann's Limit) :一个由最小的元件构成的相当于地球质量的最快的计算机,从地球诞生时一直计算到现在,可以处理的信息小于 10^{93} bits 。
所以说,当我们需要处理大规模的问题时,还需要考虑图灵机是否遇到了指数爆炸,这是我们判断我们的方法是否有效的很好的警告灯。
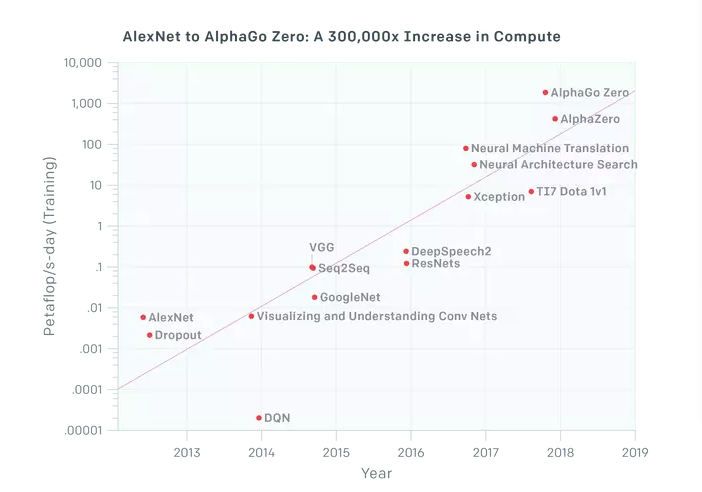
目前的人工智能似乎在算法的效率上也开始陷入了瓶颈期,需要有一次算力的巨大进步来带动解决效率的提升。为了说明这个问题,Piekniewski给出了深度学习拓展的极限:多场景、数据爆炸的情况下高速处理的能力尚且不足。
图片来源:Piekniewski. AI Winter is Well on its Way
人工智能vs人的智能
人工智能本事就是对人的智能过程的模拟,而控制人的智能过程的器官是大脑。但是目前,我们对于大脑如何控制认知过程还所知甚少,因此想要做到很好的模拟效果可谓长路漫漫,尤其是对于人脑是如何解决指数爆炸的问题,我们还没有很好的定论,但是人脑既然进化出了可以回避指数爆炸的算法,那么我们也许可以从进化论中看到解决问题的曙光。
从认知科学的角度上讲,目前的算法要想模拟人的认知,还有很大差距,这些差距的存在也是我们今后努力的方向。比如2018年,Natalie Fratto就提出了基于人脑遗忘过程提高机器决策灵活度的模型。
这里我们将人工智能分成弱人工智能,强人工智能和超人工智能来分析。
弱人工智能
弱人工智能是指不能真正地推理和解决问题的智能机器,这些机器只不过看起来像是智能的,但是并不真正拥有智能,也不会有自主意识。也就是说,弱人工智能擅长于处理某个单方面的问题。典型的就是AlphaGo在围棋领域的能力已经超过了世界最为优秀的棋手,但是其仍然是弱人工智能。
目前我们还处于弱人工智能的阶段,而这个阶段其实已经存在不少问题了。
首先,人和机器从客观世界得到的(输入信息)都是模式信息,在处理模式信息时,人和机器存在着本质的区别。人对模式的处理是基于对比的,也就是说我们认识事物很多时候对其绝对值感受不深,但是对差异比较敏感,这种对比很难找到量化标准。我们有时甚至会选择性弱化一部分条件,增强另一部分条件,来达到想要的认知效果。
举一个例子来说明这个问题:在动漫里,通常画全了鼻子嘴唇皱纹等等,人物就会显得很诡异而不好看。其原因在于我们的识别尺度。漫画人本身就是对实际人的一个简化版本,我们对这个人的五官,穿着的认知都是在简化的背景下下进行的,因此过分的加强细节形成的对比度过于明显,反而会让人产生不和谐的感觉。
而对于机器来说,量化的基础就是具体数值的引入,而对于人脑而言,对比是模糊的,不具体的,有个体差异的。寻找合理的量化准则就是今后趋近人认知过程的努力方向之一。
其次,对于智能的一个环节——分类问题而言,我们最大的问题在于有些难以找到客观的分类标准。对于以自然科学为基础的问题,我们容易找到比较客观的标准。而一旦涉及其他问题(如人文科学的问题),就没有那么容易了。丑小鸭定理说明,不存在纯客观的分类标准,人进行分类所依据的一切准则都是主观的。想让机器和人一样进行判断决策得到单个人的分类原则是可能实现的,但是在弱人工智能阶段确是没有实用价值的。
强人工智能和超人工智能
强人工智能是属于人类级别的人工智能,他在各方面都能和人类比肩,人类能干的脑力活它都能胜任。而超人工智能则在几乎所有领域都比最聪明的人类大脑都聪明很多,包括科学创新、通识和社交技能。
目前这两个阶段仍然遥不可及。目前人工智能模型还不是通用问题产生系统。也就是说,机器还不能像火箭这样的不依靠其他支撑而能够自行升空的装置。一方面,我们不清楚人是如何解决这个问题的,另一方面,机器的产生代表设计者的意志,那么这个意志是永远有边界的,这意味着我们永远需要原始的输入,这个过程是计算机不可能颠覆的。
共同的问题
人类任何的认知的目的在于预测。不论是人的认知还是机器学习,我们总是期望得到合理的预测结果。
首先,这里就产生了关于“过去能否预测未来”的哲学问题。我们以前常常调侃淘宝的推荐系统,其核心在于通过推荐系统预测我们的喜好很大程度上是不容易的。
通常情况下,绝大多数人的行为其实都是按照某种规律进行的,也就是过去如何做,未来也一般会如何做。但是这里有两个非常重要的假设性前提:一是社会现实的基础未发生大变化,另外一个是你所应用的群体,必须是样本的主体。 ——风吹江南《互联网金融》
在互联网时代,人是趋于分化的,改变的速度也越来越快,那么不仅我们可以预测的市场越来越短,而且即使个体可以预测,群体预测也是困难的。
其次,如果我们的未来是可以预测的,我们考虑他们的预测结果的影响。总体上讲,机器学习加强我们旧的认知,对产生新的认知是不利的。本质上讲,机器学习在认知上是一种趋势跟随的策略,预测结果产生的影响在没有强负面输入的情况下,病态的进行正反馈。这和我们经济泡沫产生的过程类似。因此作为个人,保持对新的认知的开口是极其重要的。但是对于人工智能,自主认识到新的认知是困难的,很可能被当作噪音处理掉了。
输入端的强不确定性
一般情况下,算法的正确率取决于使用场景的输入数据能否通过合理的模型进行量化和算法本身的效力,这里我们需要将实验室里的机器学习和实际中的机器学习应用进行区别。AI创企HuggingFace(聊天机器人)的机器学习负责人Thomas Wolf提到,实验室中的机器学习倾向于使用更复杂的模型,并在资金充足的情况下在最大规模机器用最大数据集计算,并不是所有的论文(甚至知名的论文)都有好的想法。
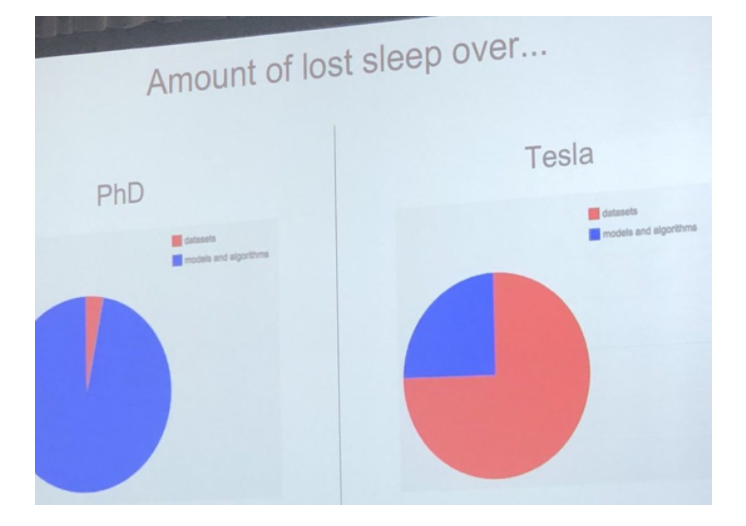
首先,更复杂的模型和更高的物理算力往往是有成本的。随着数据集大小的增加,运算效果和运算时间之间必须进行权衡。这里典型的例子是2017年Netflix公布了其没有在实际中应用2016年获得百万美金的推荐算法的原因,其核心就是由于模型复杂,投入实际应用的时候需要的算力成本是巨大的。
同时,实验室的机器学习是基于静态、干净数据的,而实际问题中我们遇到的数据往往是带有杂质,随着时间不断指数级增加的。在Train AI 2018会议上,主办人Andrej Karpathy在演讲中提到:实际问题中,处理数据所需要的时间往往是算法层面的3倍左右。因此,可见输入端对于实际过程中人工智能的应用效果至关重要。
图片来源:Lisha Li
对于人工智能需要的数据输入是否会产生问题,我认为很大程度上取决于输出结果是否是预测导向的。对于非预测的问题,即所有结果都在答案库中,人工智能可以操纵的空间是比较小的,目前这个领域我们实现的最好。
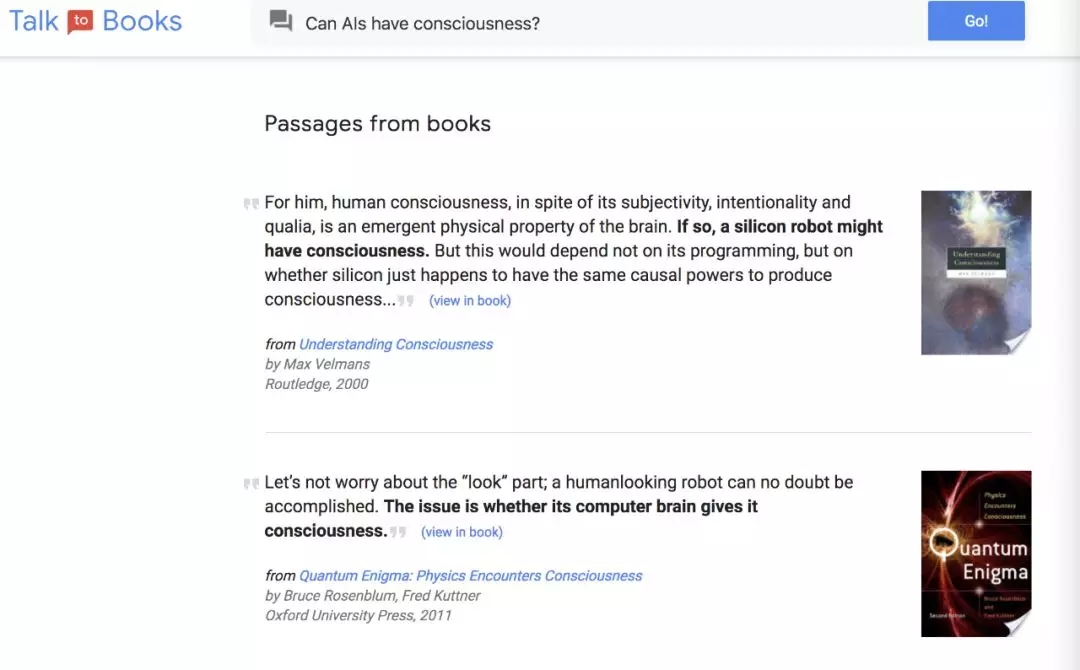
这里不得不提到Google18年4月新推出的功能“Talk to Books“:我们输入我们想问的问题,输出的结果是Google Books里面可能提供答案的书籍的排序,同时搜索结果还包括书中对于这个问题的答案的引用。因为答案答案有限,操纵输入往往没有意义。
而对于无限答案集合的问题,往往输入数据准确与否的重要性比算法的优劣更大。这种情况下,输入端往往存在3个问题:
输入端的第一个问题是判别噪声的问题,而目前的人工智能,在很多领域尚欠自主的判断能力,这就为现在操纵输入的问题提供了空间,同时若其中有利润机会,那么操纵输入更是有强动力的。如果不断用错误的语料训练模型,模型就会越来越偏离正常水平,“我浙天下第一”就是一个很好的例子。
输入端的第二个问题是信噪比的问题。在量化交易上,这个问题是最主要的。市场是具有群体性的,从这种群体性中往往噪声比例很高,提取有效信息虽然是可能的,但是这需要极强的个人能力,同时我们还不能确定有效信息的有效时长。
输入端的第三个问题是数据的不完整性。这种不完整性来源于两个方面,一是时间截面完整数据获取的高成本,而是时间不断推进而我们每次取数据只能得到一个时间断点前的所有数据。这两个问题在建立风控模型的问题上很突出:首先,如果不完全一个人/企业的全部方面,我们很难做出合理的借贷决策;同时,黑天鹅事件是频发的,过去没有违约记录的个人/企业在经济危机期间也并不能保证不违约,对于系统性风险的前瞻性判断是困难的。
人工智能应用场景的探讨
从以上的各种局限性上来看,短期内人工智能做到完全取代人是希望渺茫的。当然,如果我们完全因为以上存在的问题而否认人工智能能为我们带来的好处,也是不理性的。我认为通常情况下,某个算法在某个使用场景的使用程度取决于应用场景的容错率的高低。
低容错率场景
容错率低的应用场景指的是错误会带来严重后果的场景,典型是与人的财富和生命直接相关的。
第一个应用场景就是无人驾驶领域。目前,我们的人工智能对路况处理和响应的能力已经可以达到95%。这个正确率的绝对值但是着并不意味着目前已经具备了实践的可能性。如果全部车辆都是用无人驾驶,100辆车中5辆车会出现车祸(不能确定车祸严重性,但是有丧命的可能)是可以接受的吗?我想大概是不可接受的。甚至将来真的有一天正确率可以达到99.9%,我想也许很多人还是会对其应用产生怀疑,这里还没有考虑在正确率已经到达95%的情况下,再次优化一小步,代价都可能和达到95%正确率的代价相当。所以在无人驾驶领域人工智能还需要进行更多的努力,百度想在这个领域做出成绩是困难的,尤其在大牛吴恩达离职的背景下。
从特斯拉AutoPilot的事故中看,似乎无人驾驶就是深度学习首先受挫的领域之一,Piekniewski提到2018年初Musk就公布了东西海岸穿越计划,截至6月,这个计划还是没有实现。其实在无人驾驶领域,主要的障碍有三:一是目前的传感器和无线网的延迟问题(即使5G未来似乎可见);二是没有任何证据显示目前我们可以做到短时间巨大的数据吞吐;三是即使前两个问题完全解决的情况下短时间算法依然无法达到预期要求的极高准确率。
因此,我们目前应该从辅助驾驶谈起,无人驾驶似乎还遥不可及。
第二个应用场景金融领域。任何的金融决策都和人的财富利益息息相关,因此在金融上,我们可以看到,任何打的变化都会被能的被排斥,稳定性更为重要。这就注定了人工智能如果不能提供人可以理解的投资逻辑,很难在金融领域代替人的工作,这是人一种本能的不信任心理。同时,也没有任何证据显示,人工智能的投资能力高于人的投资决策。如果他仅能带来社会平均收益,那么算上消耗的算力,这种投资策略很可能是入不敷出的。
谣传DeepMind 曾经悄悄潜入中国搞了个量化交易的AI专门炒A股,然后因为亏得太严重,这个项目悄悄的停掉了。
也许有人在这里会给出文艺复兴公司的成功作为反例,但是我们必须需要说明,文艺复兴公司的成功带有极大的偶然性和个人能力(研究人员的强密码学血统),以这个例子来讲一个模式普遍意义上的可应用程度是不合理的。当然,通过人工智能提高投资决策效率是十分有效的。
高容错率场景
目前人工智能应用效果较好的领域普遍是容错率较高的,也就是说相对意义上,错误带来的后果不是不可原谅的。比如淘宝的推荐系统,微博的可能有兴趣的人,Google翻译等等,对于一个小小的错误,我们往往会体现宽容,甚至为我们提供了饭后的笑料和谈资。
任何创新似乎都是从这样的领域中开始的。
对于人工智能,其实我们完全没有恐慌的必要,反而应该促进其发展。未来人工智能具有无限的想象空间,但这一切都构建于认知科学和电子器件的进步之上,所以任何无限纠结于算法的人工智能注定是失败的。
Reference
[1] Piekniewski. AI Winter is Well on its Way. https://blog.piekniewski.info/2018/05/28/ai-winter-is-well-on-its-way/
[2] Gary Marcus. Deep Learning: A Critical Appraisal
[3] 吴军. 为什么计算机不是万能的
[4] Natalie Fratto. Machine Un-Learning: Why Forgetting Might Be the Key to AI
[5] 陈宇. 互联网金融